
White Cube/Black Box
White Cube/Black Box is a museum exhibit that showcases research findings from Fair Representation in Arts and Data, an interdisciplinary project of the University of Michigan. As the information designer on the team, I created two videos that explain parallels between biases in art museum systems and in algorithm systems to a public audience. I worked with a team of data scientists, artists and museum curators since early stages of the research process to organise ideation and co-create the narrative parts of the exhibit.
(Created with Illustrator, Procreate and After Effects)

Animated icon for White Cube/Black Box
Fair Representation in Arts and Data is a collaborative research project between the Michigan Institute of Data Science (MIDAS), Stamps School of Art and Design, and the University of Michigan Museum of Art (UMMA) that seeks to educate the public about the importance of fair representation in our Age of Big Data. Facial detection algorithms were applied to the UMMA’s digitised collection to examine how the UMMA collection (mis)represented humanity and how that representation has changed over time; the UMMA collection consists of ~24,000 artworks that were acquired over 150 years. For more information about the project, please click here.
Project team:
Deep learning image processing, analysis and data science content:
Jing Liu (MIDAS Managing Director)
Kerby Shedden (Professor of Statistics, Director of Consulting for Statistics, Computing, and Analytics Research)
Amy Lu and Xingwen Wei (graduate student researchers in Statistics)
Exhibit narrative and data visualisation:
Sophia Brueckner (Stamps School Associate Professor, Nokia Bell Labs Artist-in-Residence)
Shannon Yeung
Curatorial and technical expertise with UMMA’s collection:
David Choberka (Andrew W. Mellon Curator for University Learning and Programs)
John Turner (UMMA Senior Manager of Museum Technology)
Key Animation
The technical research can be separated into two main parts: facial detection and race classification. 21,386 pieces of digitised artworks were fed through YOLOv4, a deep learning facial detection algorithm that draws a bounding box around detected faces and gives a probability prediction for its confidence.



10,679 faces were detected from the artworks and the cropped faces were then fed through VGG-Face CNN Descriptor for race classification. The animation below visualises the changes in racial diversity in acquisitions over time, as classified by the algorithms.
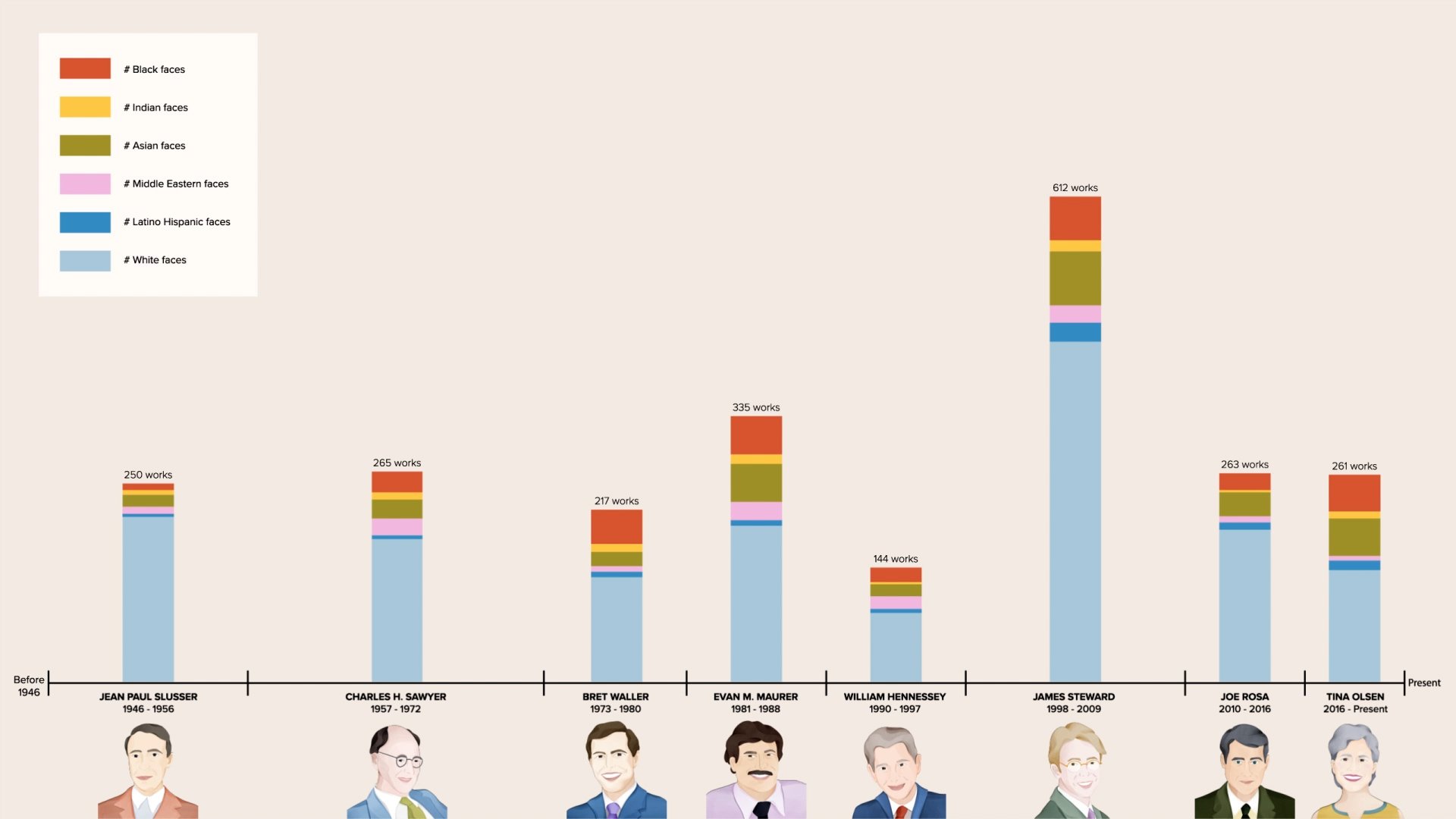
Timeline showing racial diversity of acquisitions sorted by UMMA directors

Acquisitions scaled to 100%

Acquisitions scaled to 100% and exploded for comparison

graph showing how the race representation in the collection changed over time by percentage
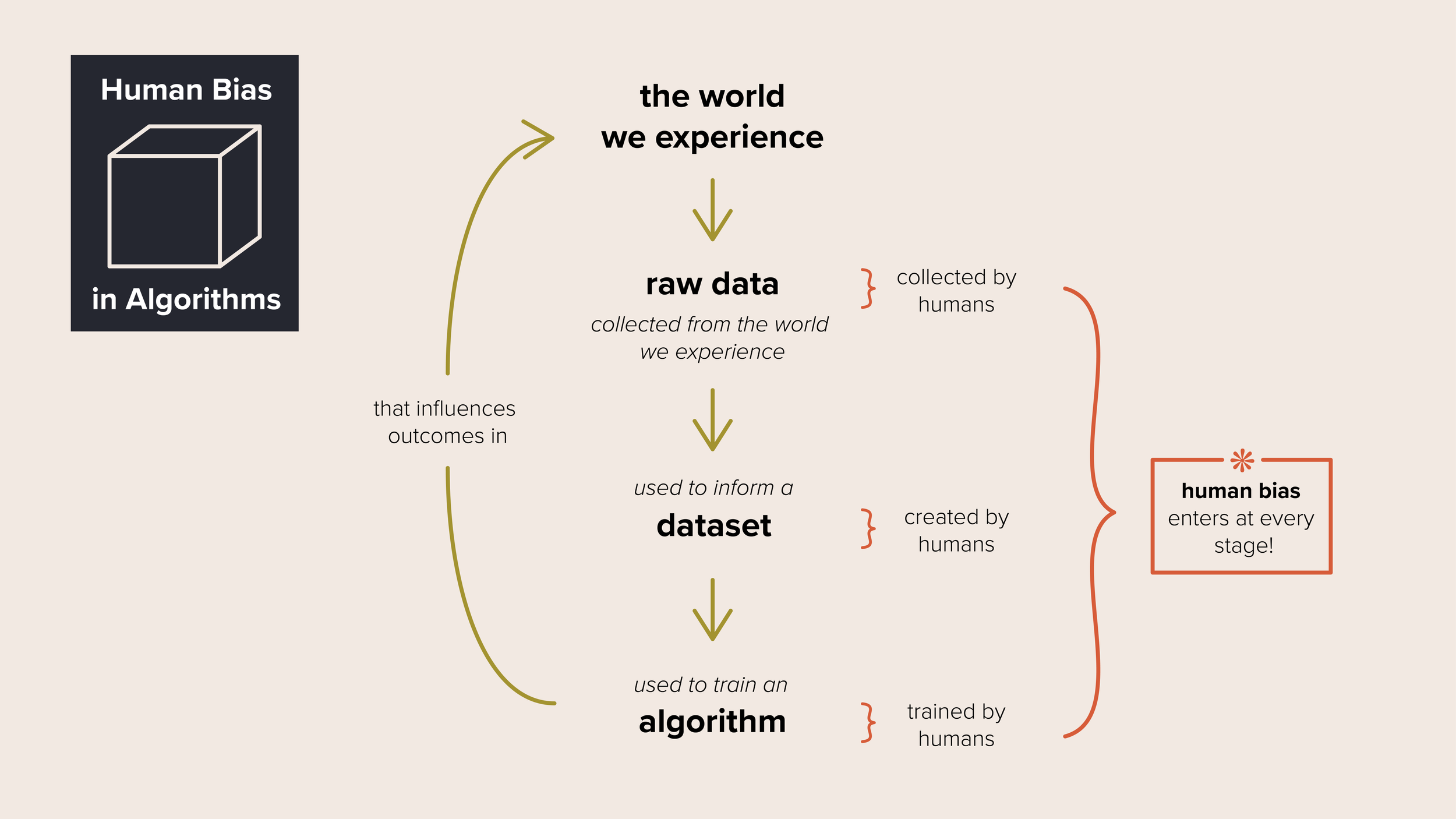
Diagram visualising how algorithms can amplify biases

Diagram visualising how bias influences art acquisition in museums
Portrait Illustrations:

White Cube/Black Box exhibit: A Commentary on Bias
While faces were indeed detected from the artworks, not all detections were reliable. The algorithm sometimes worked surprisingly well and other times made errors a human judge would never make. The algorithmic analysis, despite only successful in a limited way, was enough to examine some biases in the museum collection. Equally important, if not more so, the project was used to explore ways to build scientist-artist collaboration and to raise public awareness on the need for equitable, inclusive and non-discriminatory use of data and algorithms. It is important to note that this project should not be seen as an endorsement of using algorithms to evaluate artworks but rather an experiment to see how they would perform as well as offer a tangible case study to ground criticism of algorithms as tools. To contextualise and explain the project to museum visitors, I created two videos exhibited side by side and designed to be viewed one after the other.

Poster design for White Cube/Black Box

Videos exhibited at the University of Michigan Museum of Art
Part 1 (left) explains:
How algorithms were used to examine bias in the museum’s art acquisition practices over its 150-year history
How bias enters museum and algorithm systems
Widespread application of algorithms in society and some questionable results
Racial diversity of acquisitions made by UMMA directors (this is the key animation mentioned above)
Video text written mostly by Dave and Sophia, proofread by others
Part 2 (right) explains:
Surprising successes, false positives and false negatives from the algorithm outputs
Eigenfaces, a way to understand which features are most important in facial detection for the algorithm
Notable results and analysis sparked from algorithm outputs
Video text written mostly by Dave and Sophia, proofread by others